大数据分析中,都会用到csv数据文件,这篇文章我们讲讲如何将csv中的数据导入到hbase中,方便数据的查看,计算。也方便在后续的程序中可以直接从数据库中读取数据。
下面的程序实现了如下功能:
- 将csv文件从本地上传到hdfs文件系统中。
- 在hbase中创建表。
- 把hdfs中的csv数据导入新建的表中。
- 执行每一步,打印出提示信息。
1 | import os |
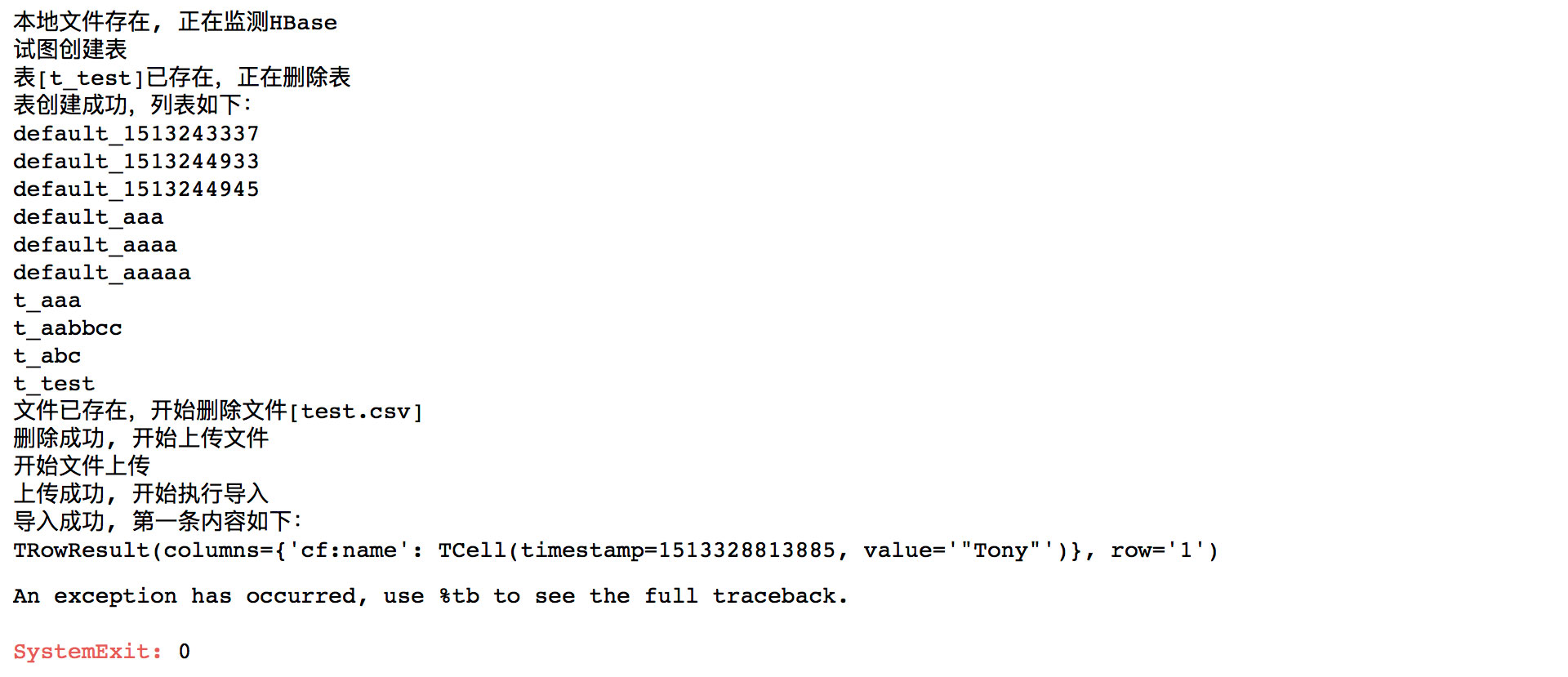
执行完成后,会在Jupyter中打印如下信息:
本系列文章《目录》
大数据分析中,都会用到csv数据文件,这篇文章我们讲讲如何将csv中的数据导入到hbase中,方便数据的查看,计算。也方便在后续的程序中可以直接从数据库中读取数据。
下面的程序实现了如下功能:
1 | import os |
执行完成后,会在Jupyter中打印如下信息:
本系列文章《目录》