这篇文章我们将按照规划方案配置HDFS,从4台中任一选择一台进行配置,本文选择node0。
Quick Start
下载及Java配置
登陆官方网站,下载hadoop.tar.gz文件,本文所使用的版本为2.7.4,下载完成后解压并进入该文件夹,修改etc/hadoop/hadoop-env.sh文件
1 | JAVA_HOME=/opt/jdk1.8.0_65 |
HDFS配置
配置etc/hadoop/hdfs-site.xml,将下面的XML标签项添加在<configuration>标签内。
注:配置项中需要填写IP地址的地方,强烈推荐填写IP地址,不要使用主机名。(在访问页面时,方便大家在不做hosts文件修改时,正常跳转)服务名
1 | <property> |
NameNode服务的名字
1 | <property> |
NameNode的RPC协议与端口
配置该项后,可以通过程序调用8020接口,RPC协议主要用于系统内部通信以及用户编程访问。
1 | <property> |
NameNode的HTTP协议与端口
配置该项后,可以通过浏览器访问50070接口
1 | <property> |
固定配置,客户端通过该类找到active的NameNode
1 | <property> |
SSH安全
1 | <property> |
JournalNode的地址与端口
1 | <property> |
JournalNode的工作目录
1 | <property> |
ZKFC自动切换
1 | <property> |
打开权限控制
1 | <property> |
slaves文件配置方式
配置datanode时,如果不是使用了主机名加DNS解析或者hosts文件解析的方式,而是直接使用ip地址去配置slaves文件
1 | <property> |
CORE配置
配置etc/hadoop/core-site.xml,将下面的XML标签项添加在<configuration>标签内。
NameNode入口
1 | <property> |
ZooKeeper地址与端口
1 | <property> |
NameNode原数据存储目录
1 | <property> |
其他配置项
指定DataNode地址
在etc/hadoop文件下,创建slaves文件,内容如下:
注:此处可以填写IP地址,也可填写主机名,推荐IP地址,保持配置一致性1 | node1的IP |
分发工具
因为Hadoop会使用到所有的服务器,所以你必须将它分发到你所有的机器节点上,本教程一共4台服务器,所以将Hadoop文件夹分发到其他3台。
1 | scp -r /opt/hadoop-2.7.4 root@node1:/opt |
启动JournalNode
按照规划我们并没有把JournalNode服务部署在所有服务器节点上,所以,这里需要分别启动node1,node2,node3上的JournalNode进程。
1 | sbin/hadoop-daemon.sh start journalnode |
使用jps命令查看是否启动成功,显示PID JournalNode则为成功。
格式化NameNode
就像我们新装windows操作系统一样,需要磁盘格式化,从而建立该系统的元数据。
在node0与node1之间,选择任一选择(这里选择node0),运行如下命令:
1 | bin/hdfs namenode -format |
格式化成功后会在tmp/dfs/name/current/目录下生成fsimage元数据
启动NameNode服务
注:启动node0节点上的NameNode服务,目的是拷贝刚刚格式化好的元数据到node1中。1 | sbin/hadoop-daemon.sh start namenode |
拷贝元数据
将node0中的NameNode服务正常启动后,就可以拷贝元数据到node1中了。
注:下面这条命令必须在node1中执行。1 | bin/hdfs namenode -bootstrapStandby |
查看拷贝是否成功。可在node1中tmp/dfs/name/current/目录下查看是否生成fsimage元数据。
注:如果格式化NameNode与拷贝元数据这几步中依然出现莫名的错误,可以删除2个节点上的元数据,重新选择另一台机器(这里选择node1)从格式化NameNode步骤开始,再做一遍。(笔者之前就遇到过此类莫名其妙的问题- -!)格式化DFSZKFailoverController
进行此步之前,需要关闭所有dfs服务:
1
sbin/stop-dfs.sh
格式化ZKFC:
1
bin/hdfs zkfc -formatZK
启动HDFS服务
完成以上步骤后,就可以启动HDFS服务了,在4台节点中,任一选择一台键入命令,都可以启动所有节点的服务。这里推荐使用node0。
1 | sbin/start-dfs.sh |
访问与测试
正常启动HDFS服务后,再node1中使用jps命令看到NameNode,JournalNode,DFSZKFailoverController,DataNode服务。
HTTP访问HDFS服务
通过IP地址:50070接口,在浏览器中正常访问到HDFS。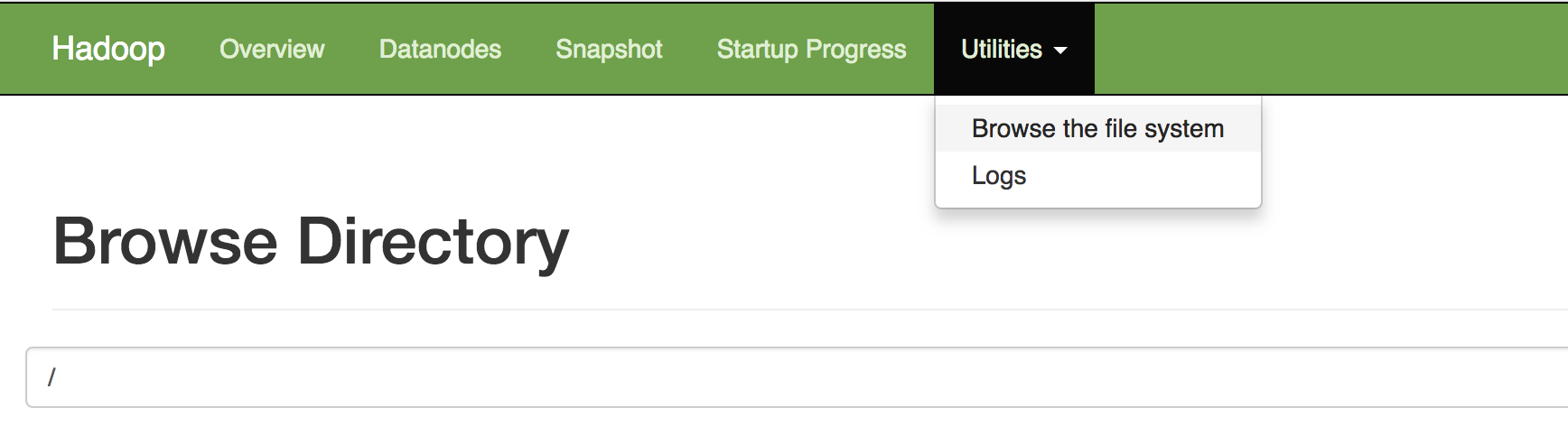
手动切换
如果启动HDFS时,两个NameNode都处于standby状态,我们也可以手动指定一台节点为激活状态。本文指定nn2(这里使用配置项中的NameNode服务名)
1 | bin/hdfs haadmin -transitionToActive --forcemanual nn2 |
HTTP访问计算引擎
通过IP地址:8088接口,在浏览器中正常访问到计算引擎。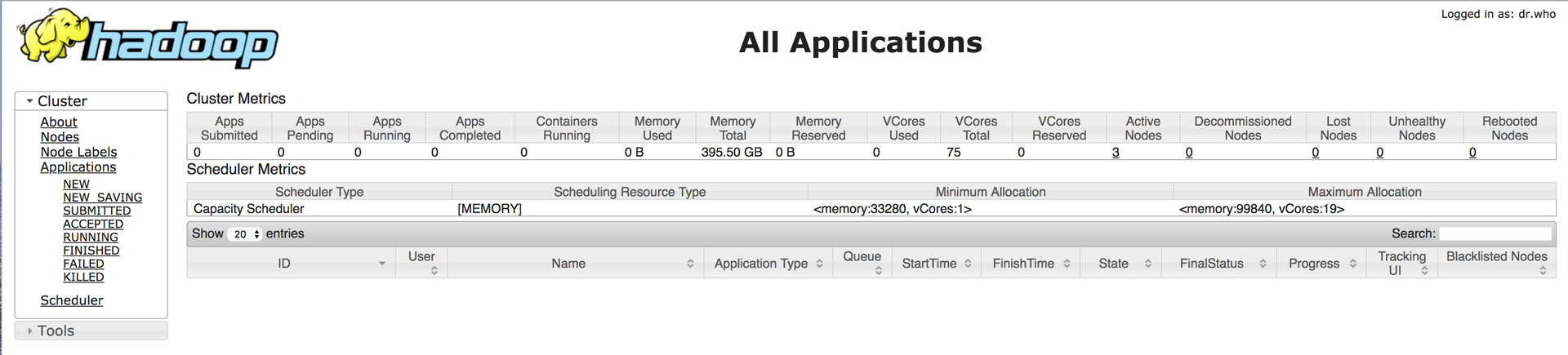
测试
创建test目录
1
bin/hdfs dfs -mkdir -p /test
上传hello.txt文件到test目录
1
bin/hdfs dfs -put hello.txt /test/
此时可以在web页面中,查看刚刚创建的文件夹
在Utilities -> Browse the file system下查看
官方文档
如果需要了解更详细的内容,请访问官方文档,文档版本3.4.10
小结
完成上述配置后,HDFS可以正常访问了,HDFS很多操作能够正常使用,MapReduce是必不可少的。随着HDFS的配置完成,说明MapReduce也配置完成。下篇文件我们开始《YARN 部署》
本系列文章《目录》