完成之前的章节,我们已经将Hadoop集群与Spark计算引擎成功部署在4个节点中了。你可以使用Java或者Scala语言(这里推荐Scala)进行开发,并可以用Spark正常进行数据挖掘了。这章我们讲HBase的部署,基本与数据存储有关。
Quick Start
下载安装
按照之前的规划表,我们会在node3中启动HBase的主进程,在node2中启动备用进程,所以在这篇文章我们选择在node3中进行配置。
登陆node3节点,并下载HBase安装包,版本1.3.1,下载完成后解压(文件目录还是统一放在/opt路径下)并进入该文件夹。
基础配置
打开conf/hbase-site.xml文件,在configuration标签中添加如下配置项:
启动集群模式
1 | <property> |
HDFS中设置HBase主目录
1 | <property> |
ZooKeeper集群地址
1 | <property> |
ZooKeeper快照存储位置
注:此项与zoo.conf中dataDir路径相同。1 | <property> |
配置元数据存储节点
HBase中的数据分为元数据(文件索引)与文件本身数据,文件数据由DataNode负责存取,元数据则由HRegionServer负责。按照规划表,我们会把元数据分布在4台节点中,所以我们需要在所有节点中部署HRegionServer,配置方法如下:
在conf文件夹中打开regionservers文件(如果未找到,新建即可)。添加如下内容:
1 | node0的IP |
配置环境变量
1 | # Java环境变量是必不可少的。 |
分发安装包
将配置好的HBase文件夹拷贝到所有节点中
1 | scp -r /opt/hbase-1.3.1 root@node0:/opt |
启动服务
在node3上执行如下命令:
1 | bin/start-hbase.sh |
执行完成后使用jps命令进行查看,node3中会有HMaster和HRegionServer服务
HA
为了达到高可用,我们需要启动一个备用进程,按照规划图,在node2中运行如下命令:
1 | bin/hbase-daemon.sh start master |
Web 访问
在浏览其中输入地址可以访问HMaster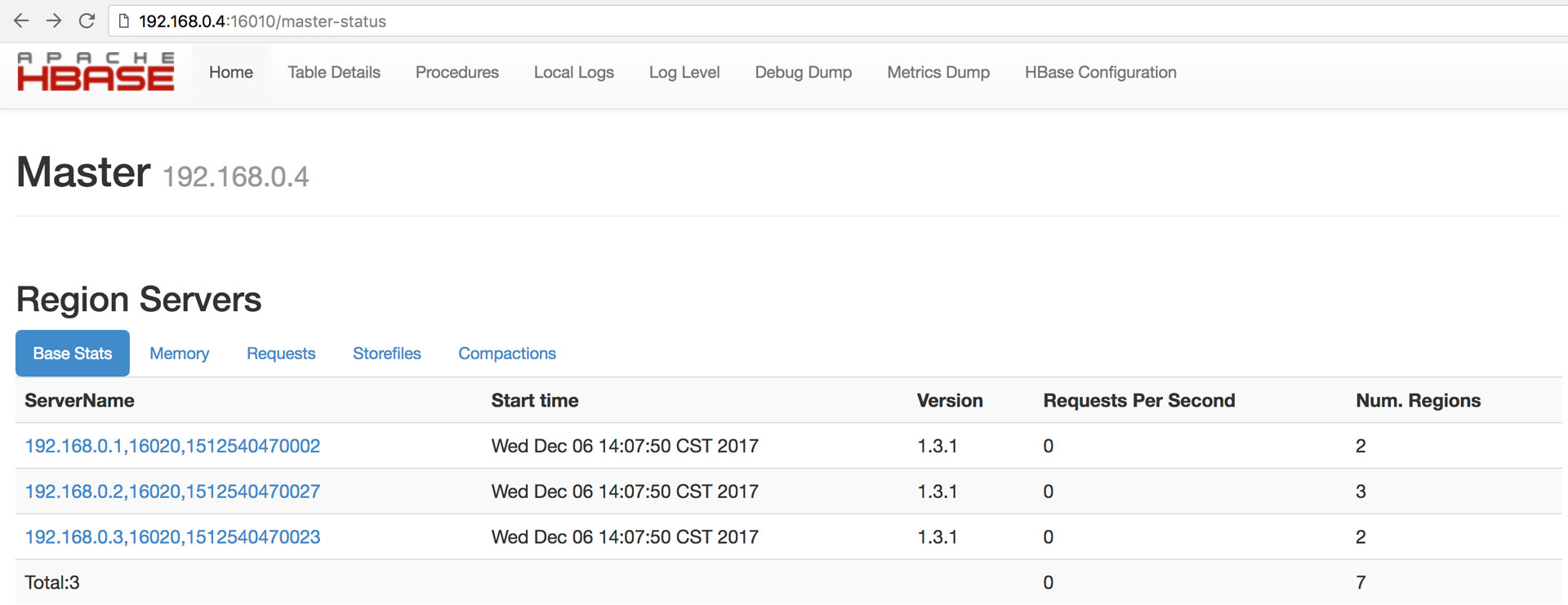
访问HRegionServer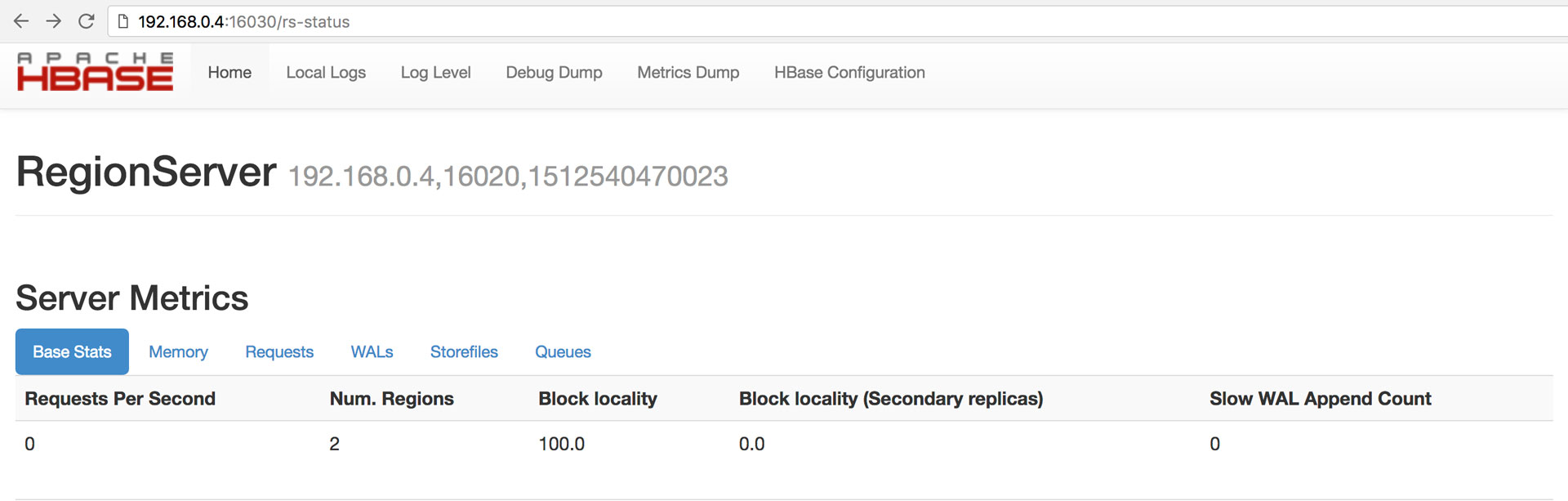
测试
SHELL
在命令行中输入如下命令,进入hbase shell界面后,可执行一些基础操作。
1 | bin/hbase shell |
创建表
1 | create '表名', '列族' |
查看所有表
1 | list |
查看表属性
1 | describe '表名' |
插入数据
1 | put '表名', 'rowkey', '列族:列', '值' |
查看表中所有数据
1 | scan '表名' |
以上是一些基础命令的测试,如果你对HBase的shell操作有更多的兴趣,请点击下方官方文档进行查阅。
官方文档
如果需要了解更详细的内容,请访问官方文档
小结
完成上述配置后,HBase可以正常访问了,基础的存储与计算都配置完成。下篇文件我们开始《Jupyter 部署》
本系列文章《目录》